Sección 5 Redes bayesianas
Los paquetes que usaremos en esta sección son:
CRAN: tidyverse (dplyr, ggplot2, purrr), bnlearn, BiocManager, igraph, gRain.
Bioconductor: Rgraphviz, RBGL
install.packages("BiocManager")
BiocManager::install("Rgraphviz")Y las referencias son Koller and Friedman (2009), Ross (1998) y Wasserman (2010).
## Warning: package 'forcats' was built under R version 3.5.2Intoducción: Modelos gráficos
Un modelo gráfico es una red de variables aleatorias donde:
Nodos representan variables aleatorias.
Arcos (dirigidos o no) representan dependencia
Los dos esquemas generales para representar dependencias/independiencias (condicionales) de forma gráfica son los modelos dirigidos (redes bayesianas) y no dirigidos (redes markovianas).
En este módulo nos enfocaremos en modelos dirigidos veamos un ejemplo de una red de seguros de auto.
En este ejemplo nos interesa entender los patrones de dependencia entre variables como edad, calidad de conductor y tipo de accidente:
#> GoodStudent Age SocioEcon RiskAversion VehicleYear ThisCarDam
#> 1 False Adult Prole Adventurous Older Moderate
#> 2 False Senior Prole Cautious Current None
#> 3 False Senior UpperMiddle Psychopath Current None
#> 4 False Adolescent Middle Normal Older None
#> 5 False Adolescent Prole Normal Older Moderate
#> 6 False Adult UpperMiddle Normal Current Moderate
#> RuggedAuto Accident MakeModel DrivQuality Mileage Antilock
#> 1 EggShell Mild Economy Poor TwentyThou False
#> 2 Football None Economy Normal TwentyThou False
#> 3 Football None FamilySedan Excellent Domino True
#> 4 EggShell None Economy Normal FiftyThou False
#> 5 Football Moderate Economy Poor FiftyThou False
#> 6 EggShell Moderate SportsCar Poor FiftyThou True
#> DrivingSkill SeniorTrain ThisCarCost Theft CarValue HomeBase AntiTheft
#> 1 SubStandard False TenThou False FiveThou City False
#> 2 Normal True Thousand False TenThou City True
#> 3 Normal False Thousand False TwentyThou City False
#> 4 Normal False Thousand False FiveThou Suburb False
#> 5 SubStandard False TenThou False FiveThou City False
#> 6 SubStandard False HundredThou False TwentyThou Suburb True
#> PropCost OtherCarCost OtherCar MedCost Cushioning Airbag ILiCost
#> 1 TenThou Thousand True Thousand Poor False Thousand
#> 2 Thousand Thousand True Thousand Good True Thousand
#> 3 Thousand Thousand False Thousand Good True Thousand
#> 4 Thousand Thousand True Thousand Fair False Thousand
#> 5 TenThou Thousand False Thousand Fair False Thousand
#> 6 HundredThou HundredThou True TenThou Poor True Thousand
#> DrivHist
#> 1 Many
#> 2 Zero
#> 3 One
#> 4 Zero
#> 5 Many
#> 6 ManyAprendemos la estructura de la red:
insurance_gm <- hc(insurance_dat, blacklist = blacklist)
graphviz.plot(insurance_gm)
#> Loading required namespace: Rgraphviz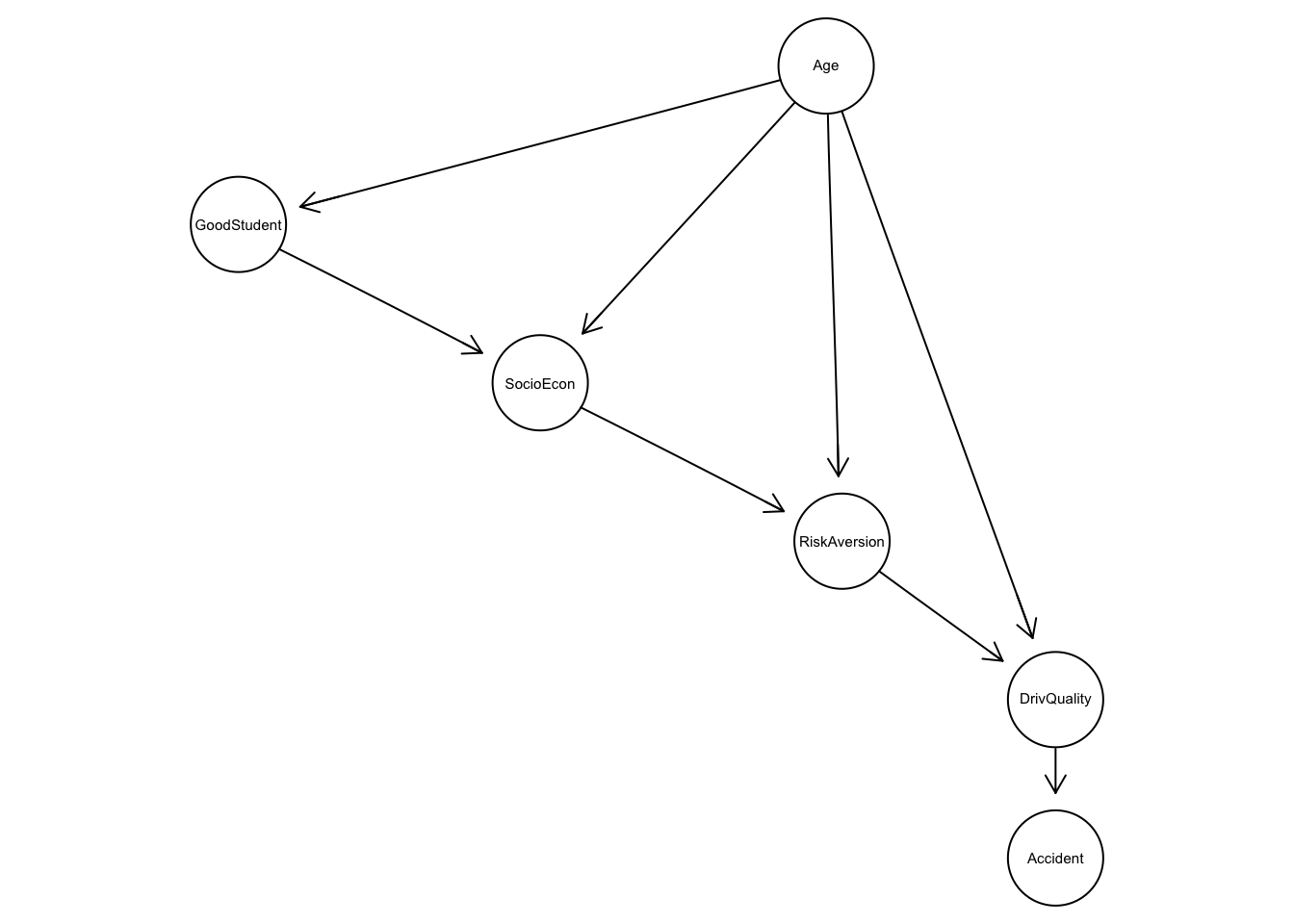
insurance.fit <- bn.fit(insurance_gm, data = insurance_dat,
method = 'bayes', iss = 1)¿Cómo interpretar esta gráfica?
Vemos por ejemplo como mucho de la asociación entre edad y tipo de accidente desaparece cuando condicionamos a calidad de conductor.
prop.table(table(insurance$Age, insurance$Accident), margin = 1)
#>
#> Mild Moderate None Severe
#> Adolescent 0.1214 0.1172 0.5734 0.1881
#> Adult 0.0844 0.0780 0.7331 0.1044
#> Senior 0.0593 0.0493 0.8137 0.0778
prop.table(table(insurance$Age, insurance$Accident, insurance$DrivQuality),
margin = c(1, 3))
#> , , = Excellent
#>
#>
#> Mild Moderate None Severe
#> Adolescent 0.01163 0.00194 0.98256 0.00388
#> Adult 0.01118 0.00437 0.98154 0.00292
#> Senior 0.00449 0.00359 0.98833 0.00359
#>
#> , , = Normal
#>
#>
#> Mild Moderate None Severe
#> Adolescent 0.01676 0.01341 0.96144 0.00838
#> Adult 0.02236 0.01110 0.96012 0.00641
#> Senior 0.02531 0.01395 0.95558 0.00517
#>
#> , , = Poor
#>
#>
#> Mild Moderate None Severe
#> Adolescent 0.19847 0.19507 0.28687 0.31959
#> Adult 0.20812 0.20861 0.29054 0.29273
#> Senior 0.19283 0.17492 0.31928 0.31296También podemos entender cómo depende calidad de conductor de edad y aversión al riesgo (modelo local para DrvQuality):
prop_tab_q <- prop.table(table(insurance$DrivQuality, insurance$RiskAversion, insurance$Age), c(2, 3))
prop_tab_q
#> , , = Adolescent
#>
#>
#> Adventurous Cautious Normal Psychopath
#> Excellent 0.1832 0.1667 0.0444 0.2195
#> Normal 0.1762 0.3519 0.4349 0.0732
#> Poor 0.6406 0.4815 0.5207 0.7073
#>
#> , , = Adult
#>
#>
#> Adventurous Cautious Normal Psychopath
#> Excellent 0.2882 0.2295 0.0964 0.2516
#> Normal 0.2413 0.4704 0.6071 0.1355
#> Poor 0.4705 0.3001 0.2965 0.6129
#>
#> , , = Senior
#>
#>
#> Adventurous Cautious Normal Psychopath
#> Excellent 0.2515 0.3751 0.1582 0.2500
#> Normal 0.1871 0.4920 0.5459 0.1136
#> Poor 0.5613 0.1329 0.2959 0.6364
df_q <- data.frame(prop_tab_q)
names(df_q) <- c('DrvQuality', 'RiskAversion', 'Age', 'Prop')
ggplot(df_q, aes(x = Age, y = Prop, colour = RiskAversion,
group = RiskAversion)) +
geom_line() + facet_wrap(~DrvQuality) +
geom_point()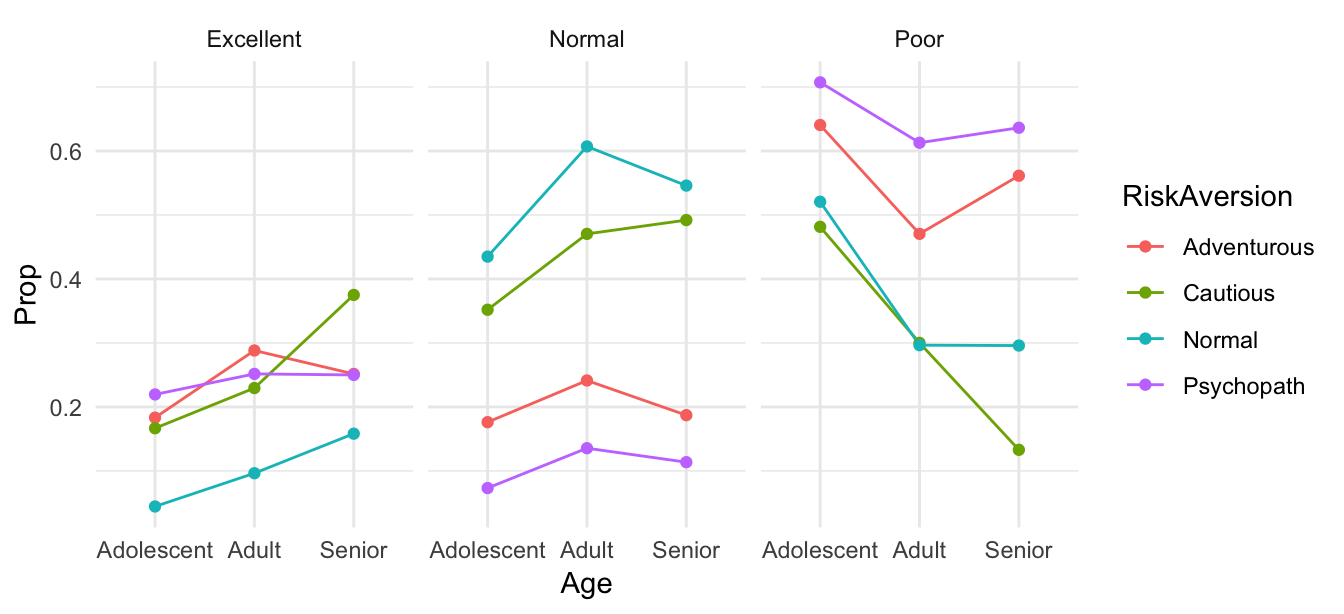
Otras asociaciones con DrvQuality podemos entenderlas a través de estas dos variables: edad y aversión al riesgo. Veremos cómo modelar estas estructuras (además de usar las tablas, que corresponden a estimación de máxima verosimilitud sin restricciones, podemos usar por ejemplo GLMs).
¿Por qué modelos gráficos?
Usando modelos gráficos podemos representar de manera compacta y atractiva distribuciones de probabilidad entre variables aleatorias.
- Auxiliar en el diseño de modelos.
Fácil combinar información proveniente de los datos con conocimiento de expertos.
Proveen un marco general para el estudio de modelos más específicos. Muchos de los modelos probabilísticos multivariados clásicos son casos particulares del formalismo general de modelos gráficos (mezclas gaussianas, modelos de espacio de estados ocultos, análisis de factores, filtro de Kalman,…).
Juegan un papel importante en el diseño y análisis de algoritmos de aprendizaje máquina.
Referencias
Koller, Daphne, and Nir Friedman. 2009. Probabilistic Graphical Models: Principles and Techniques - Adaptive Computation and Machine Learning. The MIT Press.
Ross, Sheldon M. 1998. A First Course in Probability. Fifth. Upper Saddle River, N.J.: Prentice Hall.
Wasserman, Larry. 2010. All of Statistics: A Concise Course in Statistical Inference. Springer Publishing Company, Incorporated.