8.2 Aprendizaje de la estructura de la red
Además de poder crear la estructura de un red manualmente, también es posible crearla a partir de los datos mediante algoritmos de aprendizaje de la estructura.
Hay tres tipos principalees de algoritmos de aprendizaje de la estructura de una red: basados en restricciones, basados en puntajes e híbridos (alguna mezcla de los dos anteriores). E usuario puede especifica un criterio de valoración AIC (Akaike Information Criterion), BIC (Bayesian Information Criterion) o BDE (Bayesian Dirichlet) para la determinación de la mejor estructura de la red. Los algoritmos usan diferentes técnicas para iterar en torno a las varias estructuras posibles de una red y entonces elige la mejor, dependiendo de la calificación que produzca. El método de calificación usado por defecto con los algorítmmos basados en puntajes o los bpibridos es el BIC.
Basado en restricciones No se utiliza ninguna estructura de modelo de arranque/inicio con estos algoritmos. Los algoritmos construyen la estructura buscando dependencias condicionales entre las variables. bnlearn incluye los siguientes algoritmos basados en restricciones:
Grow-Shrink (GS)
Asociación Incremental Markov Blanket (IAMB)
Asociación Incremental Rápida (Fast-IAMB)
Asociación Incremental Interleaved (Inter-IAMB)
Max-Min Parents & Children (MMPC)
Hiton-PC semi-intercalada (SI-HITON-PC)
8.2.1 Basado en la puntuación:
El usuario aprovecha su conocimiento del sistema para crear una red, codifica su confianza en la red e ingresa los datos. El algoritmo luego estima la estructura del modelo más probable. bnlearn incluye los siguientes algoritmos basados en puntuación:
Escalada simple (HC)
Tabu Search (Tabu)
Híbrido:
Mezcla de métodos basados en restricciones y basados en puntajes. bnlearn incluye los siguientes algoritmos híbridos:
Max-Min Hill Climbing (MMHC)
Maximización restringida general de 2 fases (RSMAX2)
Ahora veamos un ejemplo del aprendizaje basado en restricciones que utiliza el algoritmo de Manta de Markov con Asociación Incremental (IAMB):
iambex <- iamb(asia) #structure learning
iambex##
## Bayesian network learned via Constraint-based methods
##
## model:
## [A][S][T][L][X][D][B|S:D][E|T:L]
## nodes: 8
## arcs: 4
## undirected arcs: 0
## directed arcs: 4
## average markov blanket size: 1.50
## average neighbourhood size: 1.00
## average branching factor: 0.50
##
## learning algorithm: IAMB
## conditional independence test: Mutual Information (disc.)
## alpha threshold: 0.05
## tests used in the learning procedure: 180
## optimized: FALSEplot(iambex)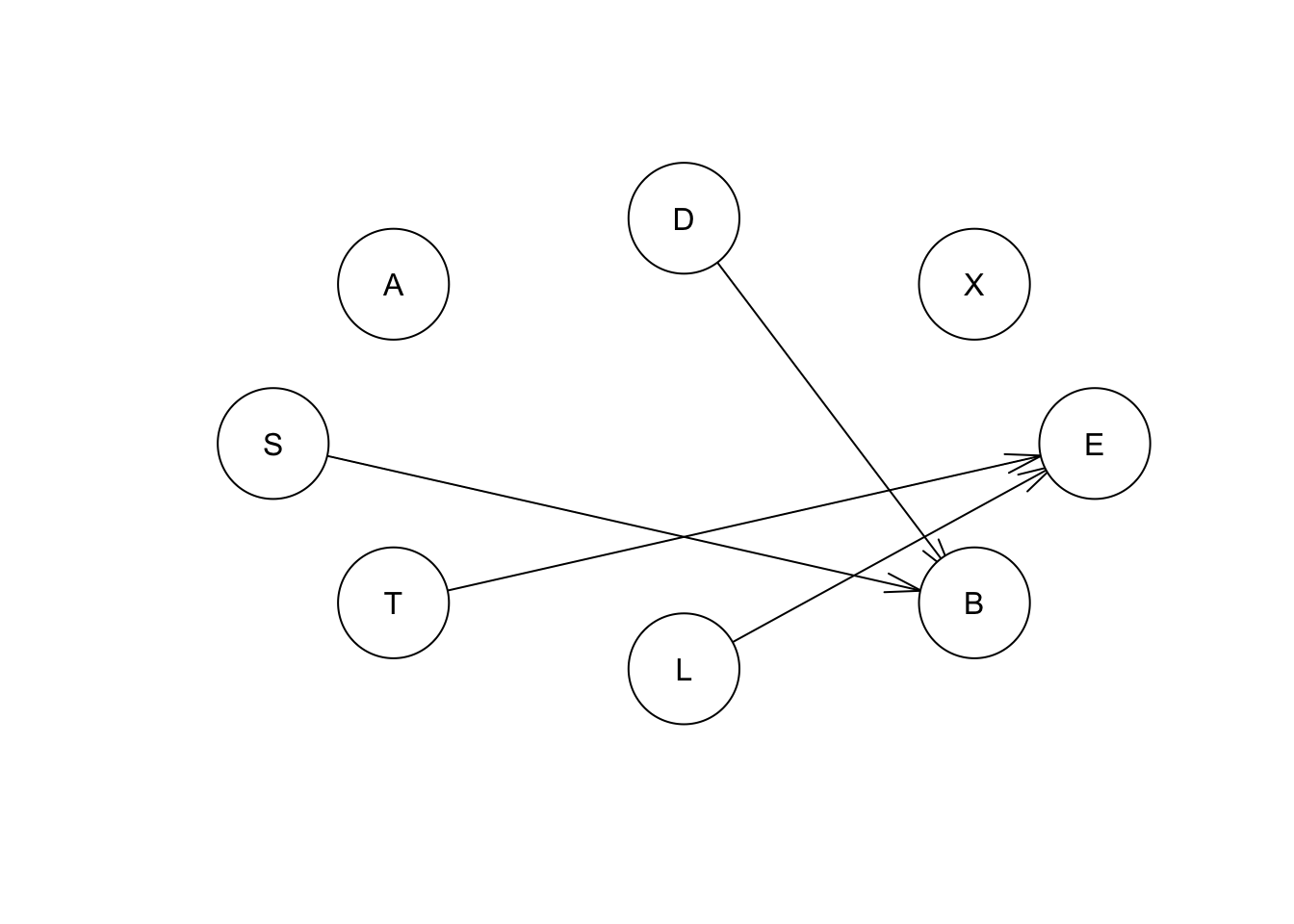
Ahora, un ejemplo de aprendizaje basado en puntuación usando el algoritmo de escalada simple (HC):
hcex <- hc(asia)
hcex##
## Bayesian network learned via Score-based methods
##
## model:
## [A][S][T][L|S][B|S][E|T:L][X|E][D|B:E]
## nodes: 8
## arcs: 7
## undirected arcs: 0
## directed arcs: 7
## average markov blanket size: 2.25
## average neighbourhood size: 1.75
## average branching factor: 0.88
##
## learning algorithm: Hill-Climbing
## score: BIC (disc.)
## penalization coefficient: 4.258597
## tests used in the learning procedure: 77
## optimized: TRUEmmex <- mmhc(asia)
mmex##
## Bayesian network learned via Hybrid methods
##
## model:
## [A][S][T][X][L|S][B|S][E|T:L][D|B]
## nodes: 8
## arcs: 5
## undirected arcs: 0
## directed arcs: 5
## average markov blanket size: 1.50
## average neighbourhood size: 1.25
## average branching factor: 0.62
##
## learning algorithm: Max-Min Hill-Climbing
## constraint-based method: Max-Min Parent Children
## conditional independence test: Mutual Information (disc.)
## score-based method: Hill-Climbing
## score: BIC (disc.)
## alpha threshold: 0.05
## penalization coefficient: 4.258597
## tests used in the learning procedure: 339
## optimized: TRUEplot(mmex)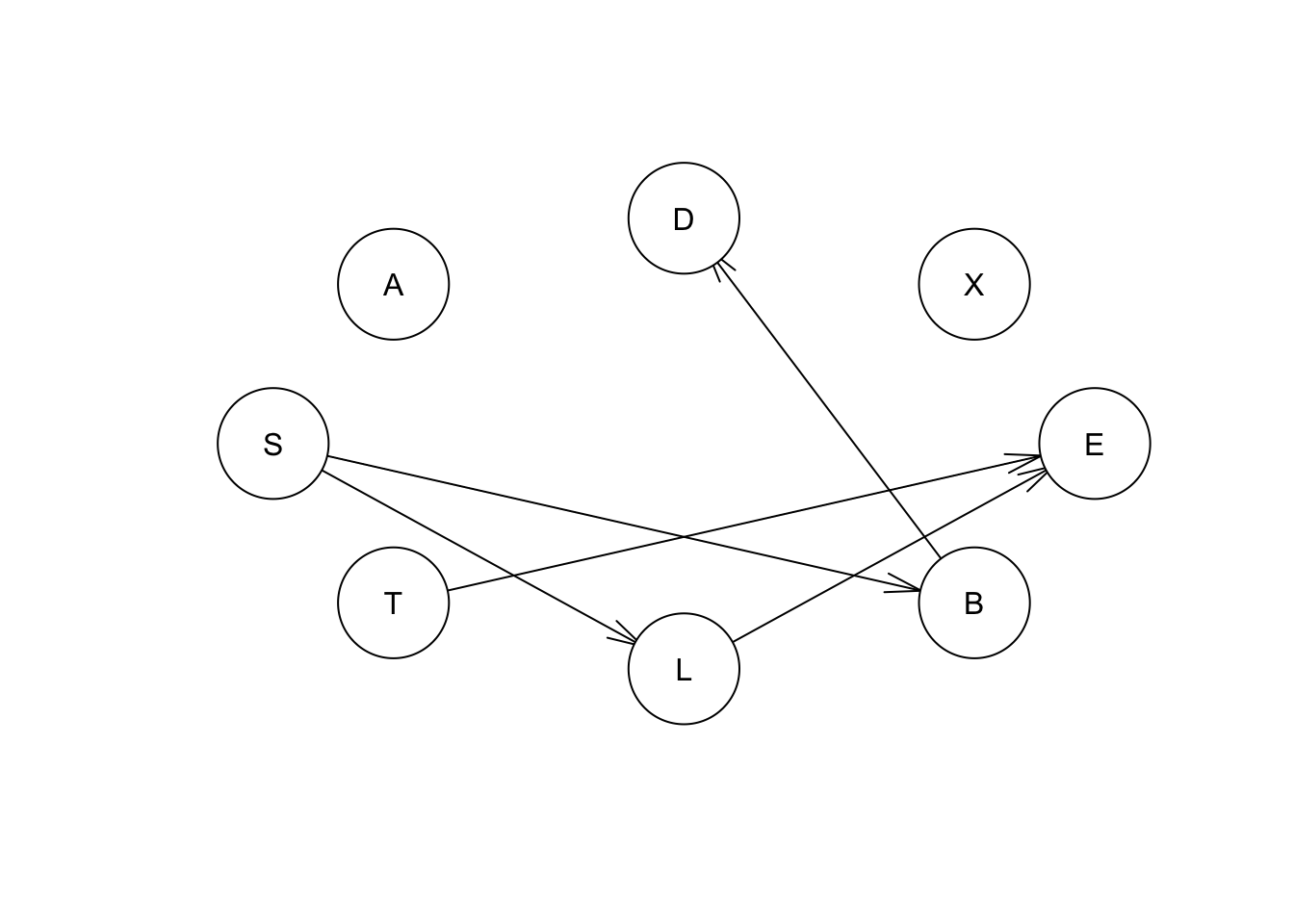 ### Redes por puntajes
### Redes por puntajes
A continuación se muestran ejemplos de las puntuaciones de AIC y BDE para la mejor red en el algoritmo de escalada simple (HC), aplicando el algorítmmo de aprendizaje basado en la puntuación que se muestra más arriba.
score(hcex,asia,type="aic") #getting aic value for full network## [1] -11051.9score(hcex,asia,type="bde") #getting bde value for full network## [1] -11095.79Los resultados del algoritmo anterior también proporcionan un buen ejemplo de lo que sucede cuando la “mejor” estructura de red, no contiene arcos para todos los nodos. La red del algoritmo basado en puntuaciones es la más cercana a la red “verdadera”, pero el nodo A no está conectado a la red. Podemos investigar por qué este es el caso con el nodo A. Por ejemplo, del modelo verdadero sabemos que el nodo A influye en el nodo T. Calculemos la puntuación de A a T, y luego de T a A.
#setting arcs to get actual scores from individual relationships
eq.net = set.arc(hcex, "A", "T")
#setting arcs to get actual scores from individual relationships
eq.net1 = set.arc(hcex,"T", "A")
puntaje_net = score(eq.net, asia, type="aic") #retriving score
puntaje_net1 = score(eq.net1, asia, type="aic") #retriving score
plot(eq.net)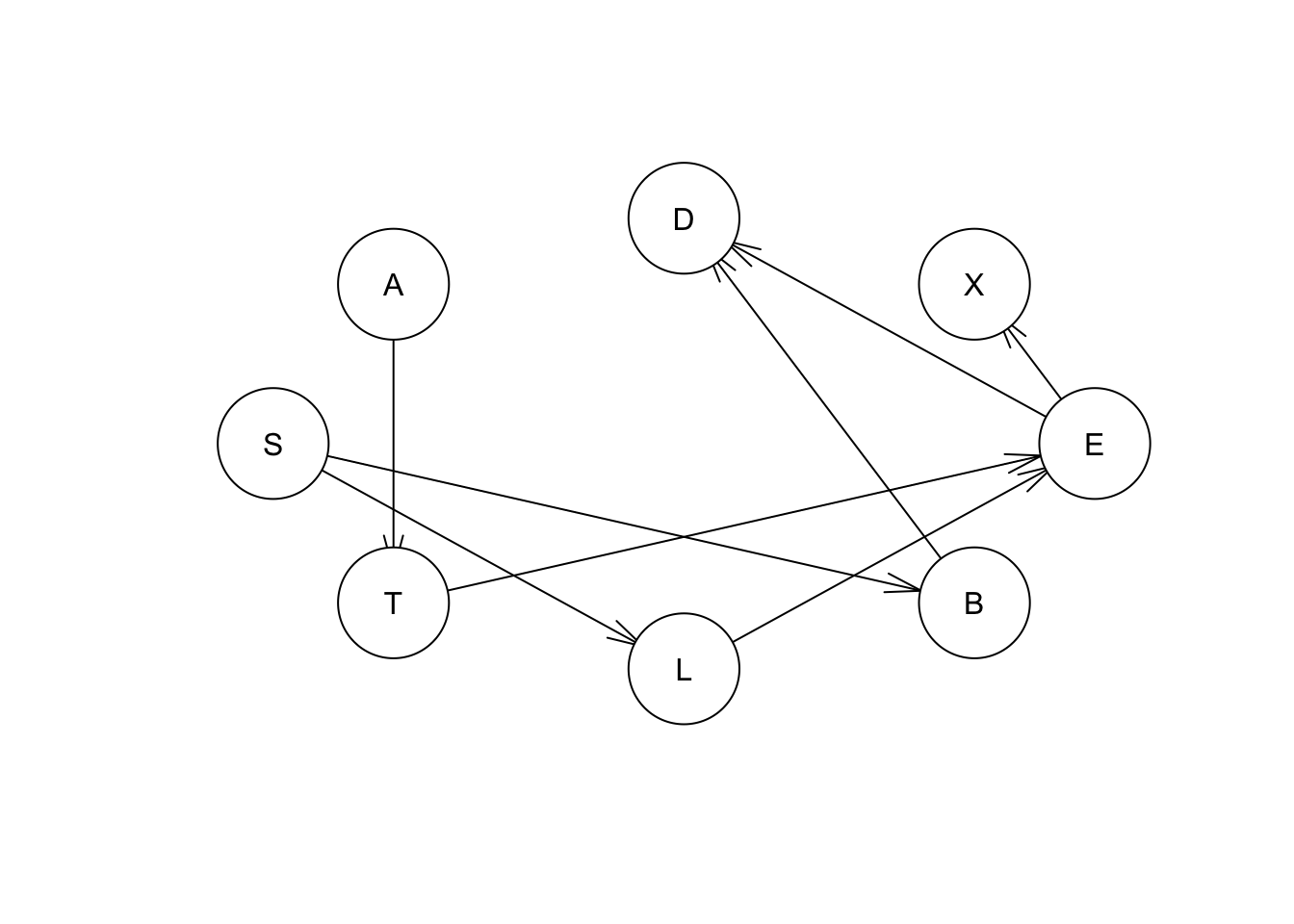
plot(eq.net1)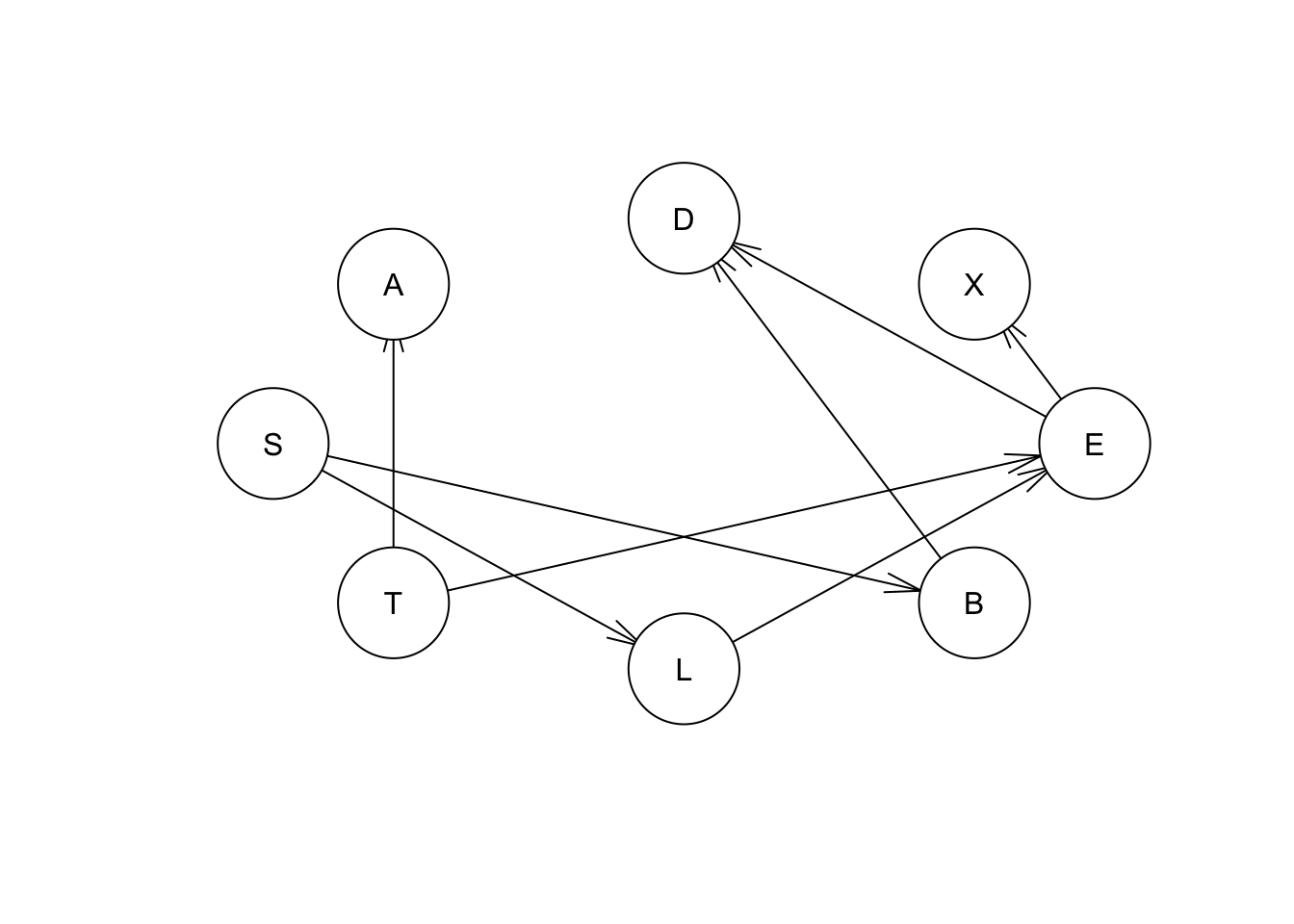 Con estos comandos obtenemos el puntaje que está sociado con relaciones particulares:
Con estos comandos obtenemos el puntaje que está sociado con relaciones particulares:
| Red | puntaje |
|---|---|
| “net” | -11051.09 |
| “net1” | -11051.09 |
Vemos que cuando establecemos el arco de A a T, o de T a A, obtenemos la misma puntuación de red (-11051.09). Por lo tanto, la relación entre A y T se denomina “puntuación equivalente”, ya que cualquier dirección proporciona la misma puntuación de red equivalente. Cambiar la dirección del vínculo entre dos nodos no cambia la puntuación de red.
Por otro lado, si cambiamos la dirección de la flecha entre otros dos nodos que incluyen otras interconexiones en la red, veremos el cambio de la puntuación de la red. Por ejemplo, si cambiamos la relación entre los nodos L y E:
eq.net = set.arc(hcex, "L", "E")
eq.net1 = set.arc(hcex,"E", "L")
score(eq.net, asia, type="aic")## [1] -11051.9plot(eq.net)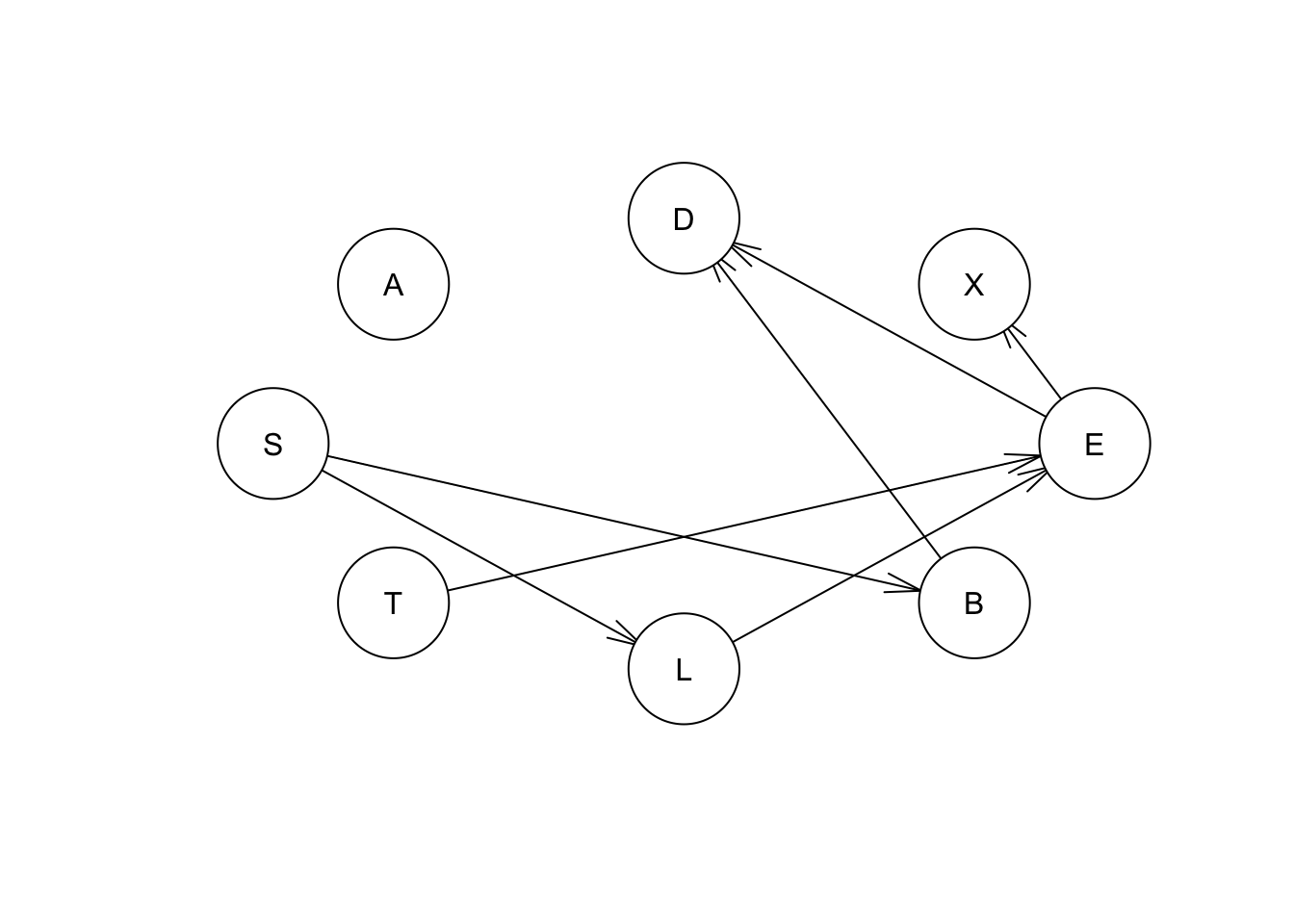
plot(eq.net1)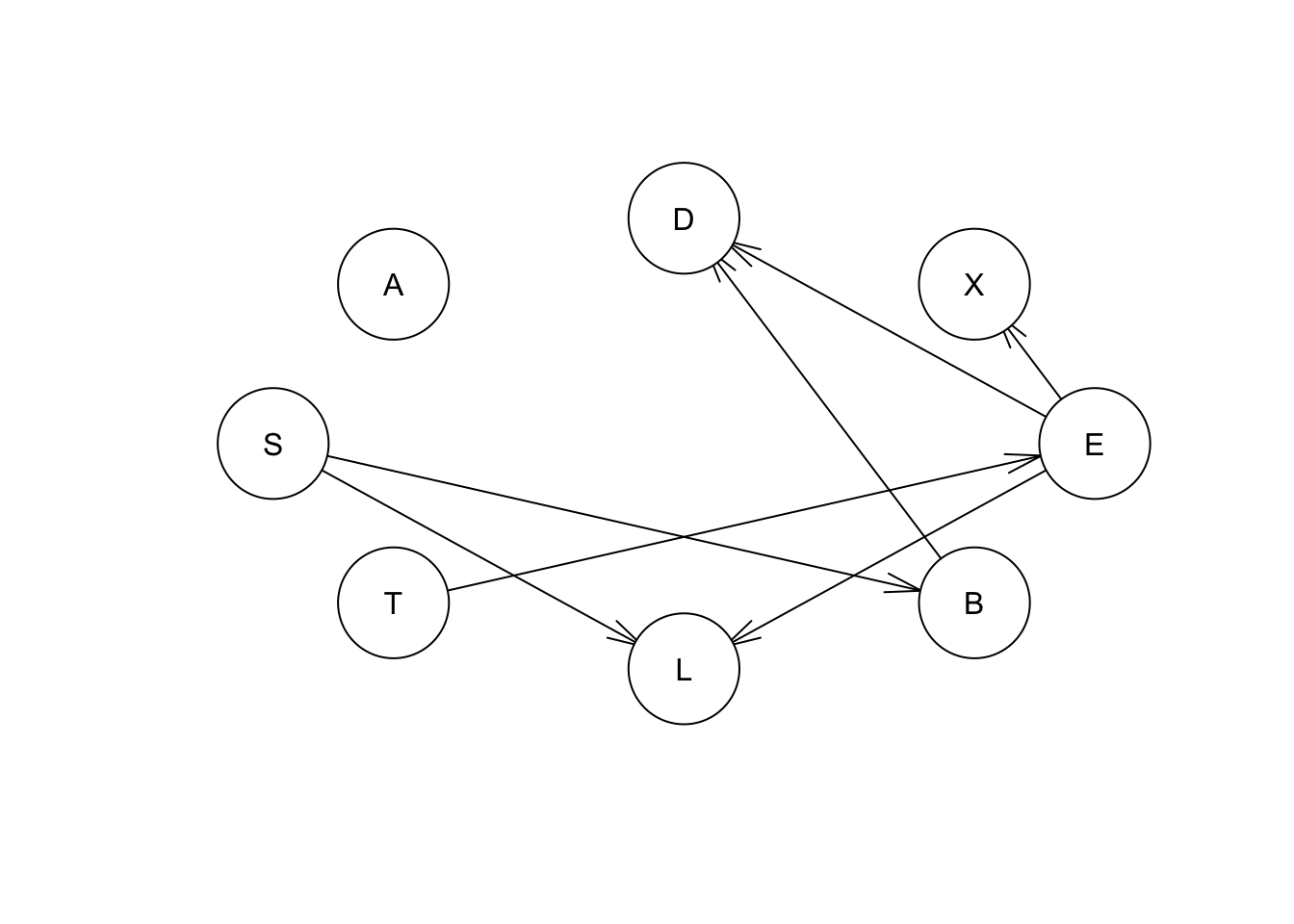
puntaje_net = score(eq.net,asia, type="aic")
puntaje_net1 = score(eq.net1,asia, type="aic")El resultado de este cambio es el siguiente:
| Red | puntaje |
|---|---|
| “net” | -11051.897 |
| “net1” | -11271.589 |
Vemos que la puntuación de la red disminuye cuando invertamos la dirección entre los nodos L y E.
En este punto, dado que los algoritmos no han podido determinar la relación de A a T (u otros nodos), es posible que queramos recurrir a la literatura, la opinión “experta”, la teoría de la ecología, etc. para argumentar la mejor relación entre el nodo A y el nodo T o el resto de la estructura.